빅데이터/빅데이터Hadoop
빅데이터 하둡 프로그래밍 교육과정 ]Interactive Job Flow
행복한짱짱이
2017. 4. 7. 20:04
빅데이터 하둡 프로그래밍 교육과정 ]Interactive Job Flow
빅데이터 하둡 프로그래밍 교육과정 ]Interactive Job Flow

실무개발자를위한 실무교육 전문교육센터학원
www.oraclejava.co.kr에 오시면 보다 다양한 강좌를 보실 수 있습니다.
Interactive Job Flow
■앞서 언급한 위저드형식의 ElasticMapReduce Job Launcher이다.
■ AWS 콘솔에서 실행하던지
http://console.aws.amazon.com/elasticmapreduce/home를 방문.
■ 위저드를 통해 코드의 위치, 입출력위치, 필요한 서버의 수와 타입등을 지정한다.
■ Create New Job Flow 버튼을 클릭
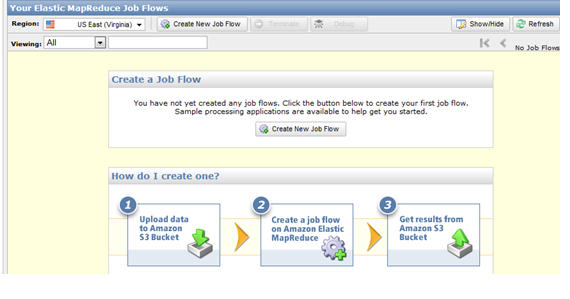
■ 이제 Define Job Flow 팝업이 뜨는데 Job Flow Name을 적당히 주고 원하는 하둡버전을 택한다 (0.20.205).
마지막으로 Create a Job Flow 섹션에서는 그냥 기능을 테스트해보기 위해서 “Run a sample application”을 택하고 드롭다운에서 Word Count(Streaming)을 선택.
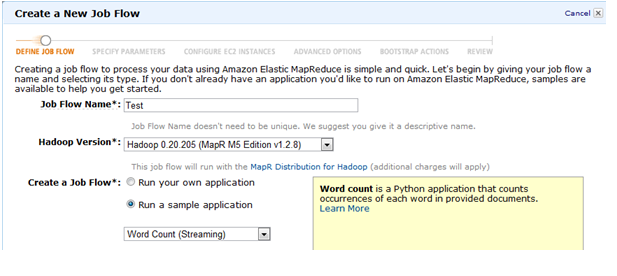
■ 다음 화면은 잡의 파라미터를 지정해주는 부분이다 (코드와 입출력파일 위치). 입력파일과 코드들(mapper, reducer)는
디폴트로 지정되는 것을 사용하면 되지만 출력은 자신만의 S3 버킷을 지정해야 한다.
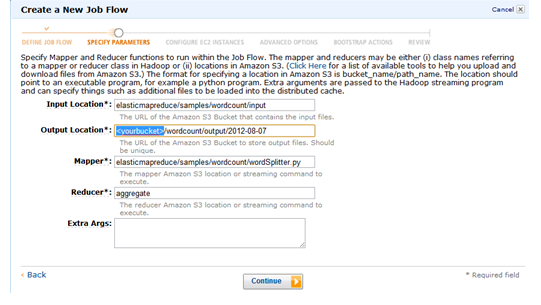
■ 다음은 Configure EC2 INSTANCES 화면이다. 여기서는 몇대의 서버를 어떤 타입으로 실행할지 결정한다.
마스터 인스턴스는 1대가 꼭 필요하며 Core Instance Group에서 Large (m1.large)로 1대나 2대를 할당한다 (Task Instance는 0로 남겨둔다).
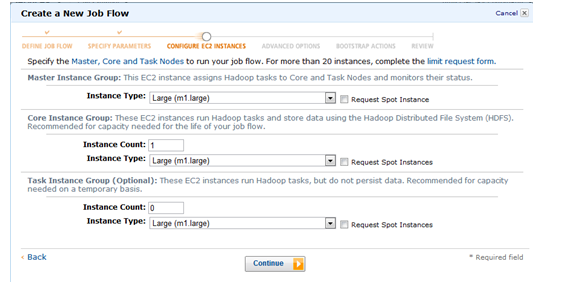
■ Advanced Options와 Boostrap Actions은 디폴트를 그대로 택한다.
■ 마지막 Review 페이지에서 “Create Job Flow” 버튼을 클릭한다.
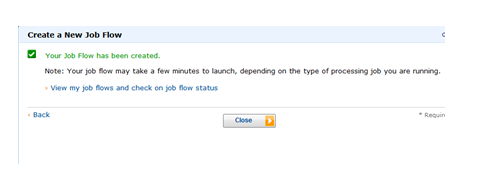
■ 그러면 아래와 같은 팝업이 뜨면서 실행이 시작되었음을 알린다.
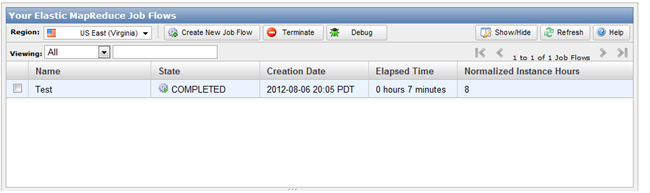
■ ElasticMapReduce 콘솔로 가보면 지금 실행한 잡의 상태를 볼 수 있다.
■ 실행이 완료되었으면 반드시 Terminate한다.
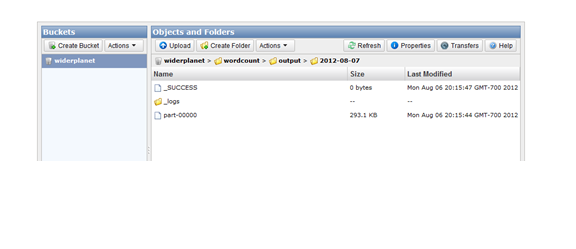
■마지막으로 앞서 지정한 S3 출력 위치로 가서 아웃풋이 제대로 만들어졌는지 확인한다.